What this capability really covers
This page covers two related layers. SnapTables provide the live operational records the system works on while tasks are still in motion. Retrieval and vectorisation extend that data layer so documents and structured records can also be searched, recalled, and used in later reasoning.
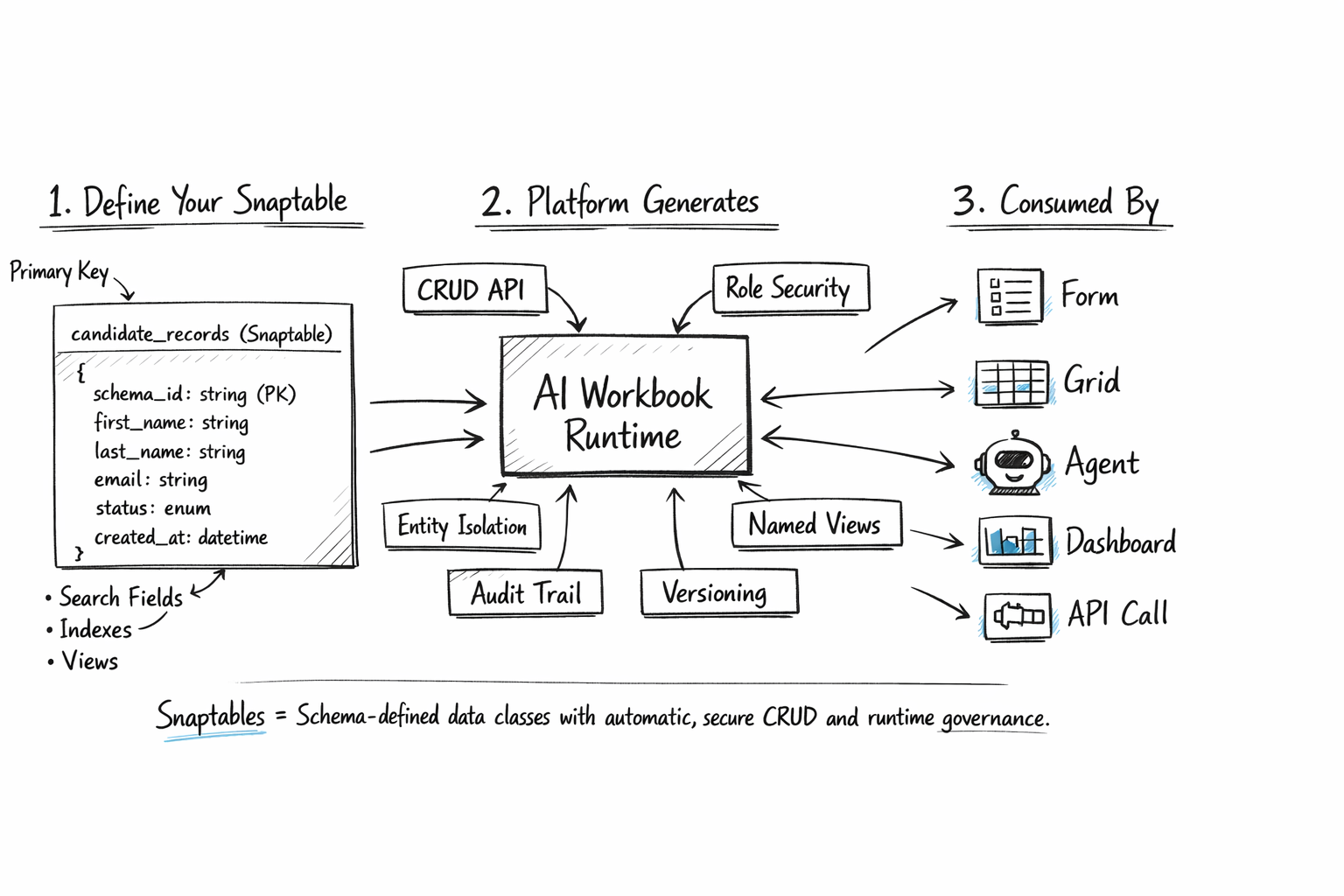
Why it matters
Why it matters
Shared structure
Important records follow explicit shapes instead of drifting into inconsistent storage patterns.
Operational visibility
Teams can understand live state without rebuilding the data layer for every workflow.
Usable retrieval
Documents and structured records can become searchable, retrievable assets instead of static files or hidden rows.
What value it brings
What value it brings
Faster system formation
New operational flows can reuse a common record model instead of starting from zero.
Lower integration friction
Entry points, workflows, assistants, and connected systems can all work against the same data contract.
Better knowledge reuse
Retrieval can draw on indexed documents and structured records instead of forcing teams back to manual searching.